

Πώς γίνονται οι άνθρωποι τόσο επιδέξιοι; Λοιπόν, αρχικά δεν είμαστε, αλλά από τη βρεφική ηλικία, ανακαλύπτουμε και εξασκούμε όλο και πιο περίπλοκες δεξιότητες μέσω του αυτοεπιβλεπόμενου παιχνιδιού. Αλλά αυτό το παιχνίδι δεν είναι τυχαίο – η βιβλιογραφία για την ανάπτυξη του παιδιού προτείνει ότι τα βρέφη χρησιμοποιούν την προηγούμενη εμπειρία τους για να διεξαγάγουν κατευθυνόμενη εξερεύνηση προσόντων όπως η κινητικότητα, η απορρόφηση, η ικανότητα σύλληψης και η πεπτικότητα μέσω αλληλεπίδρασης και αισθητηριακής ανατροφοδότησης. Αυτός ο τύπος εξερεύνησης που κατευθύνεται στις προσιτές τιμές επιτρέπει στα βρέφη να μάθουν τόσο τι μπορεί να γίνει σε ένα δεδομένο περιβάλλον όσο και πώς να το κάνει. Μπορούμε να δημιουργήσουμε μια ανάλογη στρατηγική σε ένα ρομποτικό σύστημα μάθησης;
Στα αριστερά βλέπουμε βίντεο από ένα προηγούμενο σύνολο δεδομένων που συλλέγονται με ένα ρομπότ που εκτελεί διάφορες εργασίες, όπως το άνοιγμα και το κλείσιμο του συρταριού, καθώς και το πιάσιμο και τη μετατόπιση αντικειμένων. Στα δεξιά έχουμε ένα καπάκι που το ρομπότ δεν έχει ξαναδεί. Το ρομπότ έλαβε ένα σύντομο χρονικό διάστημα για να εξασκηθεί με το νέο αντικείμενο, μετά από το οποίο θα του δοθεί μια εικόνα στόχου και θα του ανατεθεί να κάνει τη σκηνή να ταιριάζει με αυτήν την εικόνα. Πώς μπορεί το ρομπότ να μάθει γρήγορα να χειρίζεται το περιβάλλον και να πιάνει αυτό το καπάκι χωρίς εξωτερική επίβλεψη;
Για να το κάνουμε αυτό, αντιμετωπίζουμε πολλές προκλήσεις. Όταν ένα ρομπότ πέφτει σε ένα νέο περιβάλλον, πρέπει να μπορεί να χρησιμοποιήσει τις προηγούμενες γνώσεις του για να σκεφτεί πιθανές χρήσιμες συμπεριφορές που προσφέρει το περιβάλλον. Στη συνέχεια, το ρομπότ πρέπει να είναι σε θέση να εξασκεί αυτές τις συμπεριφορές πληροφοριακά. Για να βελτιωθεί τώρα στο νέο περιβάλλον, το ρομπότ πρέπει στη συνέχεια να είναι σε θέση να αξιολογήσει τη δική του επιτυχία με κάποιο τρόπο χωρίς μια εξωτερική ανταμοιβή.
Εάν μπορούμε να ξεπεράσουμε αυτές τις προκλήσεις αξιόπιστα, ανοίγουμε την πόρτα για έναν ισχυρό κύκλο κατά τον οποίο οι πράκτορες μας χρησιμοποιούν την προηγούμενη εμπειρία για τη συλλογή δεδομένων αλληλεπίδρασης υψηλής ποιότητας, τα οποία στη συνέχεια αυξάνουν την προηγούμενη εμπειρία τους ακόμη περισσότερο, ενισχύοντας συνεχώς τη δυνητική τους χρησιμότητα!
Η μέθοδός μας, Visuomotor Affordance Learning, ή VAL, αντιμετωπίζει αυτές τις προκλήσεις. Στο VAL, ξεκινάμε υποθέτοντας πρόσβαση σε ένα προηγούμενο σύνολο δεδομένων ρομπότ που επιδεικνύει οικονομικές δυνατότητες σε διάφορα περιβάλλοντα. Από εδώ, το VAL εισέρχεται σε μια φάση εκτός σύνδεσης που χρησιμοποιεί αυτές τις πληροφορίες για να μάθει 1) ένα μοντέλο παραγωγής για να φανταστεί κανείς χρήσιμα οικονομικά οικονομικά σε νέα περιβάλλοντα, 2) μια ισχυρή πολιτική εκτός σύνδεσης για αποτελεσματική εξερεύνηση αυτών των προσφορών και 3) μια μέτρηση αυτοαξιολόγησης για τη βελτίωση αυτή την πολιτική. Τέλος, η VAL είναι έτοιμη για την online φάση της. Ο πράκτορας απορρίπτεται σε ένα νέο περιβάλλον και μπορεί τώρα να χρησιμοποιήσει αυτές τις μαθημένες ικανότητες για τη διεξαγωγή αυτοεποπτευόμενης μικροσυντονισμού. Όλο το πλαίσιο απεικονίζεται στο παρακάτω σχήμα. Στη συνέχεια, θα εμβαθύνουμε στις τεχνικές λεπτομέρειες της φάσης εκτός σύνδεσης και στο διαδίκτυο.
Λαμβάνοντας υπόψη ένα προηγούμενο σύνολο δεδομένων που καταδεικνύει τις επιδόσεις διαφόρων περιβαλλόντων, το VAL αφομοιώνει αυτές τις πληροφορίες σε τρία βήματα εκτός σύνδεσης: εκμάθηση αναπαράστασης για το χειρισμό δεδομένων πραγματικού κόσμου υψηλών διαστάσεων, εκμάθηση προσφορών για να επιτρέψει την αυτοεποπτευόμενη πρακτική σε άγνωστα περιβάλλοντα και εκμάθηση συμπεριφοράς για επίτευξη υψηλής απόδοσης αρχική πολιτική που επιταχύνει την αποτελεσματικότητα της διαδικτυακής μάθησης.
1. Πρώτον, το VAL μαθαίνει μια χαμηλή αναπαράσταση αυτών των δεδομένων χρησιμοποιώντας έναν αυτόματο κωδικοποιητή Vector Quantized Variational ή VQVAE. Αυτή η διαδικασία μειώνει τις εικόνες 48x48x3 σε έναν λανθάνοντα χώρο 144 διαστάσεων.
Οι αποστάσεις σε αυτόν τον λανθάνοντα χώρο έχουν νόημα, ανοίγοντας το δρόμο για τον κρίσιμο μηχανισμό της αυτοαξιολόγησης της επιτυχίας μας. Δεδομένης της τρέχουσας εικόνας s και της εικόνας στόχου g, κωδικοποιούμε και τα δύο στον λανθάνοντα χώρο και ορίζουμε την απόστασή τους για να λάβουμε μια ανταμοιβή.
Αργότερα, θα χρησιμοποιήσουμε επίσης αυτήν την αναπαράσταση ως τον λανθάνοντα χώρο για την πολιτική μας και τη συνάρτηση Q.
2. Στη συνέχεια, η VAL μαθαίνει ένα μοντέλο οικονομικής απόδοσης εκπαιδεύοντας ένα PixelCNN στον λανθάνοντα χώρο για να μάθει την κατανομή των προσβάσιμων καταστάσεων που εξαρτώνται από μια εικόνα από το περιβάλλον. Αυτό γίνεται με τη μεγιστοποίηση της πιθανότητας των δεδομένων,
$p(s_n | s_0)$. Χρησιμοποιούμε αυτό το μοντέλο απόδοσης για κατευθυνόμενη εξερεύνηση και για επανασήμανση στόχων.
Το μοντέλο affordance απεικονίζεται στο σχήμα δεξιά. Στο κάτω αριστερό μέρος του σχήματος, βλέπουμε ότι η εικόνα κλιματισμού περιέχει ένα δοχείο και οι αποκωδικοποιημένοι λανθάνοντες στόχοι επάνω δεξιά δείχνουν το καπάκι σε διαφορετικές θέσεις. Αυτοί οι συνεκτικοί στόχοι θα επιτρέψουν στο ρομπότ να πραγματοποιήσει συνεκτική εξερεύνηση.
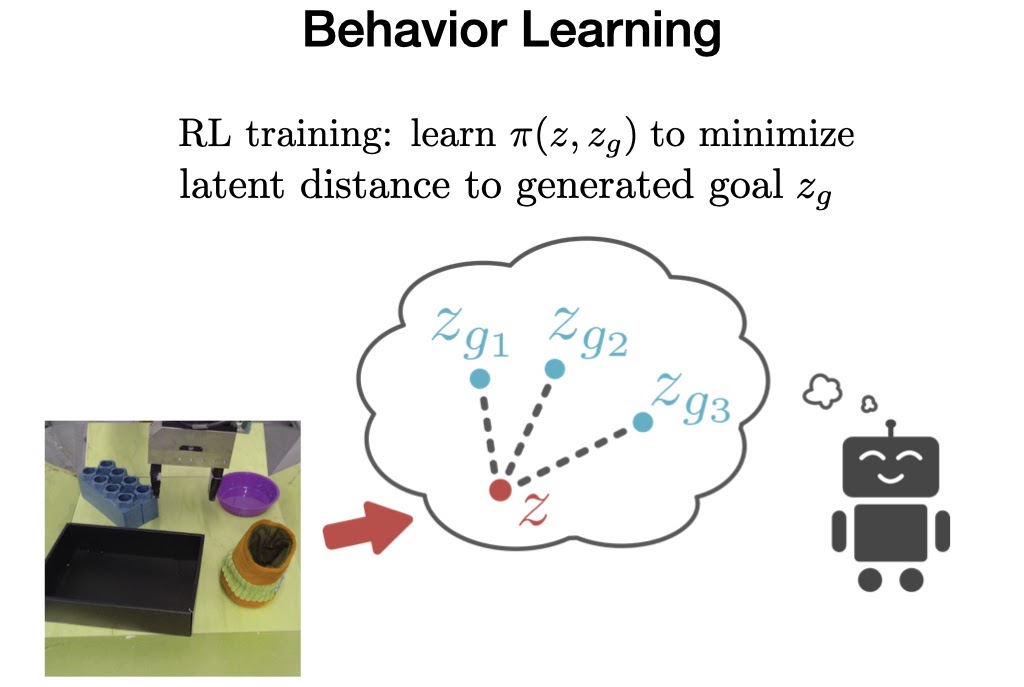
3. Τελευταία στη φάση εκτός σύνδεσης, η VAL πρέπει να μάθει συμπεριφορές από τα δεδομένα εκτός σύνδεσης, τις οποίες στη συνέχεια μπορεί να βελτιώσει αργότερα με επιπλέον διαδικτυακή, διαδραστική συλλογή δεδομένων.
Για να το πετύχουμε αυτό, εκπαιδεύουμε μια πολιτική εξαρτημένη από στόχο στο προηγούμενο σύνολο δεδομένων χρησιμοποιώντας το Advantage Weighted Actor Critic, έναν αλγόριθμο που έχει σχεδιαστεί ειδικά για εκπαίδευση εκτός σύνδεσης και είναι κατάλληλος για λεπτομέρεια στο διαδίκτυο.
Τώρα, όταν το VAL τοποθετείται σε ένα αόρατο περιβάλλον, χρησιμοποιεί τις προηγούμενες γνώσεις του για να φανταστεί οπτικές αναπαραστάσεις χρήσιμων προσφορών, συλλέγει χρήσιμα δεδομένα αλληλεπίδρασης προσπαθώντας να επιτύχει αυτά τα προσόντα, ενημερώνει τις παραμέτρους του χρησιμοποιώντας τη μέτρηση αυτοαξιολόγησης και επαναλαμβάνει τη διαδικασία. πάλι απο την αρχή.
Σε αυτό το πραγματικό παράδειγμα, στα αριστερά βλέπουμε την αρχική κατάσταση του περιβάλλοντος, που επιτρέπει το άνοιγμα του συρταριού καθώς και άλλες εργασίες.
Στο βήμα 1, το μοντέλο απόδοσης δειγματοληπτεί έναν λανθάνοντα στόχο. Με την αποκωδικοποίηση του στόχου (χρησιμοποιώντας τον αποκωδικοποιητή VQVAE, ο οποίος στην πραγματικότητα δεν χρησιμοποιείται ποτέ κατά τη διάρκεια του RL, επειδή λειτουργούμε εξ ολοκλήρου στον λανθάνοντα χώρο), μπορούμε να δούμε ότι η δυνατότητα είναι να ανοίξουμε ένα συρτάρι.
Στο βήμα 2, παρουσιάζουμε την εκπαιδευμένη πολιτική με τον στόχο του δείγματος. Βλέπουμε ότι ανοίγει με επιτυχία το συρτάρι, στην πραγματικότητα πηγαίνει πολύ μακριά και τραβώντας το συρτάρι μέχρι το τέλος. Αυτό όμως παρέχει εξαιρετικά χρήσιμη αλληλεπίδραση για τον αλγόριθμο RL ώστε να τελειοποιήσει περαιτέρω και να τελειοποιήσει την πολιτική του.
Μετά την ολοκλήρωση της ηλεκτρονικής λεπτομέρειας, μπορούμε τώρα να αξιολογήσουμε το ρομπότ σχετικά με την ικανότητά του να επιτύχει τις αντίστοιχες αόρατες εικόνες στόχου για κάθε περιβάλλον.
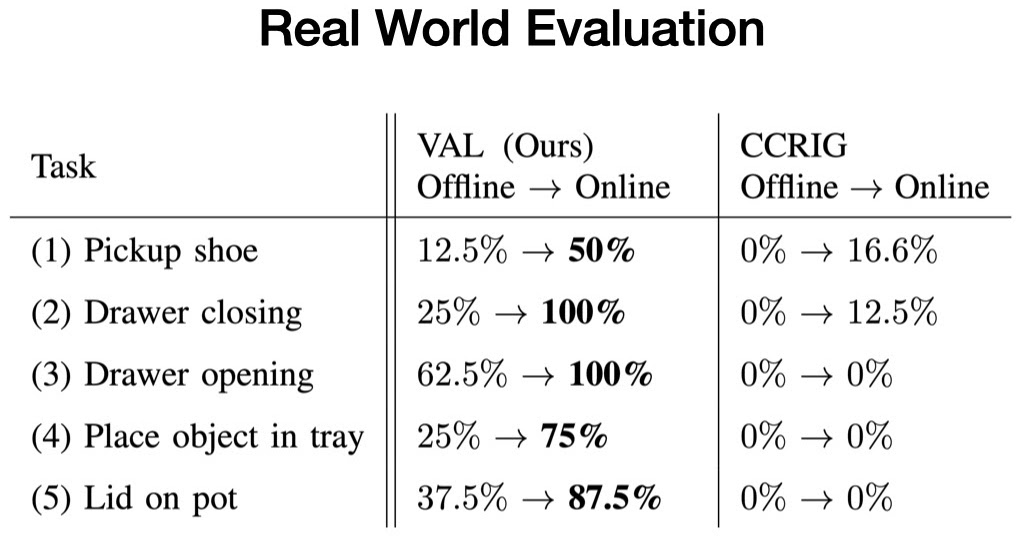
Αξιολογούμε τη μέθοδό μας σε πέντε περιβάλλοντα δοκιμών πραγματικού κόσμου και αξιολογούμε το VAL ως προς την ικανότητά του να επιτύχει μια συγκεκριμένη εργασία που παρέχει το περιβάλλον πριν και μετά πέντε λεπτά χωρίς επίβλεψη μικρορύθμισης.
Κάθε περιβάλλον δοκιμής αποτελείται από τουλάχιστον ένα αόρατο αντικείμενο αλληλεπίδρασης και δύο τυχαία δειγματοληπτικά αντικείμενα διάσπασης της προσοχής. Για παράδειγμα, ενώ υπάρχουν συρτάρια ανοίγματος και κλεισίματος στα δεδομένα εκπαίδευσης, τα νέα συρτάρια έχουν αόρατες λαβές.
Σε κάθε περίπτωση, ξεκινάμε με την πολιτική εκπαίδευσης εκτός σύνδεσης, η οποία επιλύει την εργασία ασυνεπώς. Στη συνέχεια, συλλέγουμε περισσότερη εμπειρία χρησιμοποιώντας το μοντέλο μας affordance για δείγμα στόχων. Τέλος, αξιολογούμε την τελειοποιημένη πολιτική, η οποία επιλύει με συνέπεια την εργασία.
Διαπιστώνουμε ότι σε καθένα από αυτά τα περιβάλλοντα, το VAL επιδεικνύει με συνέπεια αποτελεσματική γενίκευση μηδενικής βολής μετά από εκπαίδευση εκτός σύνδεσης, ακολουθούμενη από ταχεία βελτίωση με το σχέδιο μικρορύθμισης που κατευθύνεται στην οικονομική απόδοση. Εν τω μεταξύ, οι προηγούμενες αυτοεποπτευόμενες μέθοδοι μόλις και μετά βίας βελτιώνουν την κακή απόδοση μηδενικής βολής σε αυτά τα νέα περιβάλλοντα. Αυτά τα συναρπαστικά αποτελέσματα απεικονίζουν τις δυνατότητες που έχουν προσεγγίσεις όπως το VAL να επιτρέπουν στα ρομπότ να λειτουργούν με επιτυχία πολύ πέρα από το περιορισμένο εργοστασιακό περιβάλλον στο οποίο έχουν συνηθίσει τώρα.
Το σύνολο δεδομένων μας με 2.500 τροχιές αλληλεπίδρασης ρομπότ υψηλής ποιότητας, που καλύπτουν 20 λαβές συρταριών, 20 λαβές δοχείων, 60 παιχνίδια και 60 αντικείμενα που αποσπούν την προσοχή, είναι πλέον δημόσια διαθέσιμη στον ιστότοπό μας.
Για περαιτέρω ανάλυση, εκτελούμε το VAL σε ένα διαδικαστικά δημιουργημένο περιβάλλον πολλαπλών εργασιών με οπτική και δυναμική παραλλαγή. Ποια αντικείμενα βρίσκονται στη σκηνή, τα χρώματά τους και οι θέσεις τους τυχαιοποιούνται ανά περιβάλλον. Ο πράκτορας μπορεί να χρησιμοποιήσει λαβές για να ανοίξει συρτάρια, να πιάσει αντικείμενα για να τα μετακινήσει, να πατήσει κουμπιά για να ξεκλειδώσει τα διαμερίσματα και ούτω καθεξής.
Στο ρομπότ δίνεται ένα προηγούμενο σύνολο δεδομένων που εκτείνεται σε διάφορα περιβάλλοντα και αξιολογείται ως προς την ικανότητά του να τελειοποιήσει στα ακόλουθα περιβάλλοντα δοκιμής.
Και πάλι, με δεδομένο ένα ενιαίο σύνολο δεδομένων εκτός πολιτικής, η μέθοδός μας μαθαίνει γρήγορα προηγμένες δεξιότητες χειρισμού, όπως το κράτημα, το άνοιγμα του συρταριού, η επανατοποθέτηση και η χρήση εργαλείων για ένα διαφορετικό σύνολο νέων αντικειμένων.
Τα περιβάλλοντα και ο κώδικας αλγορίθμου είναι διαθέσιμα. παρακαλώ δείτε το δικό μας αποθετήριο κωδικών.
Όπως η βαθιά μάθηση σε τομείς όπως η όραση υπολογιστών και η επεξεργασία φυσικής γλώσσας που οδηγήθηκαν από μεγάλα σύνολα δεδομένων και γενίκευση, η ρομποτική πιθανότατα θα απαιτήσει εκμάθηση από παρόμοια κλίμακα δεδομένων. Εξαιτίας αυτού, οι βελτιώσεις στην εκμάθηση ενίσχυσης εκτός σύνδεσης θα είναι κρίσιμες για να μπορούν τα ρομπότ να εκμεταλλεύονται μεγάλα προηγούμενα σύνολα δεδομένων. Επιπλέον, αυτές οι πολιτικές εκτός σύνδεσης θα χρειάζονται είτε ταχεία, μη αυτόνομη μικροσυντονισμό είτε εντελώς αυτόνομη μικροσυντονισμό για να είναι εφικτή η ανάπτυξη σε πραγματικό κόσμο. Τέλος, όταν τα ρομπότ λειτουργούν μόνα τους, θα έχουμε πρόσβαση σε μια συνεχή ροή νέων δεδομένων, τονίζοντας τόσο τη σημασία όσο και την αξία των αλγορίθμων δια βίου μάθησης.
Αυτή η ανάρτηση βασίζεται στο άρθρο «Τι μπορώ να κάνω εδώ; Learning New Skills by Imagining Visual Affordances», το οποίο παρουσιάστηκε στο International Conference on Robotics and Automation (ICRA), 2021. Μπορείτε να δείτε τα αποτελέσματα στην ιστοσελίδα μας, και εμείς δώστε κωδικό για να αναπαράγουμε τα πειράματά μας.
ετικέτες: γ-Έρευνα-Καινοτομία

Blog BAIR
είναι το επίσημο ιστολόγιο του Berkeley Artificial Intelligence Research (BAIR) Lab.
Το BAIR Blog είναι το επίσημο ιστολόγιο του Berkeley Artificial Intelligence Research (BAIR) Lab.